

WEMC Tech Blog 5: Filename Verification with Python and JSON
In order to build and maintain a robust operational system, which relies on many datasets, file naming becomes an important factor in identifying and describing the data contained within.
In the case of climate science, this could involve descriptors such as data origin, bias adjustment, variable type, start/end dates, accumulated or instantaneous measurements, grid resolutions etc.
This example uses a JSON (JavaScript Open Notation) file as a lookup table. JSON files are extremely lightweight and can be imported easily by most modern programming languages. In Python, these are imported as a dictionary data type, which behaves like a list of objects. In this example, it will technically be a ‘nested’ dictionary, as it has multiple levels.
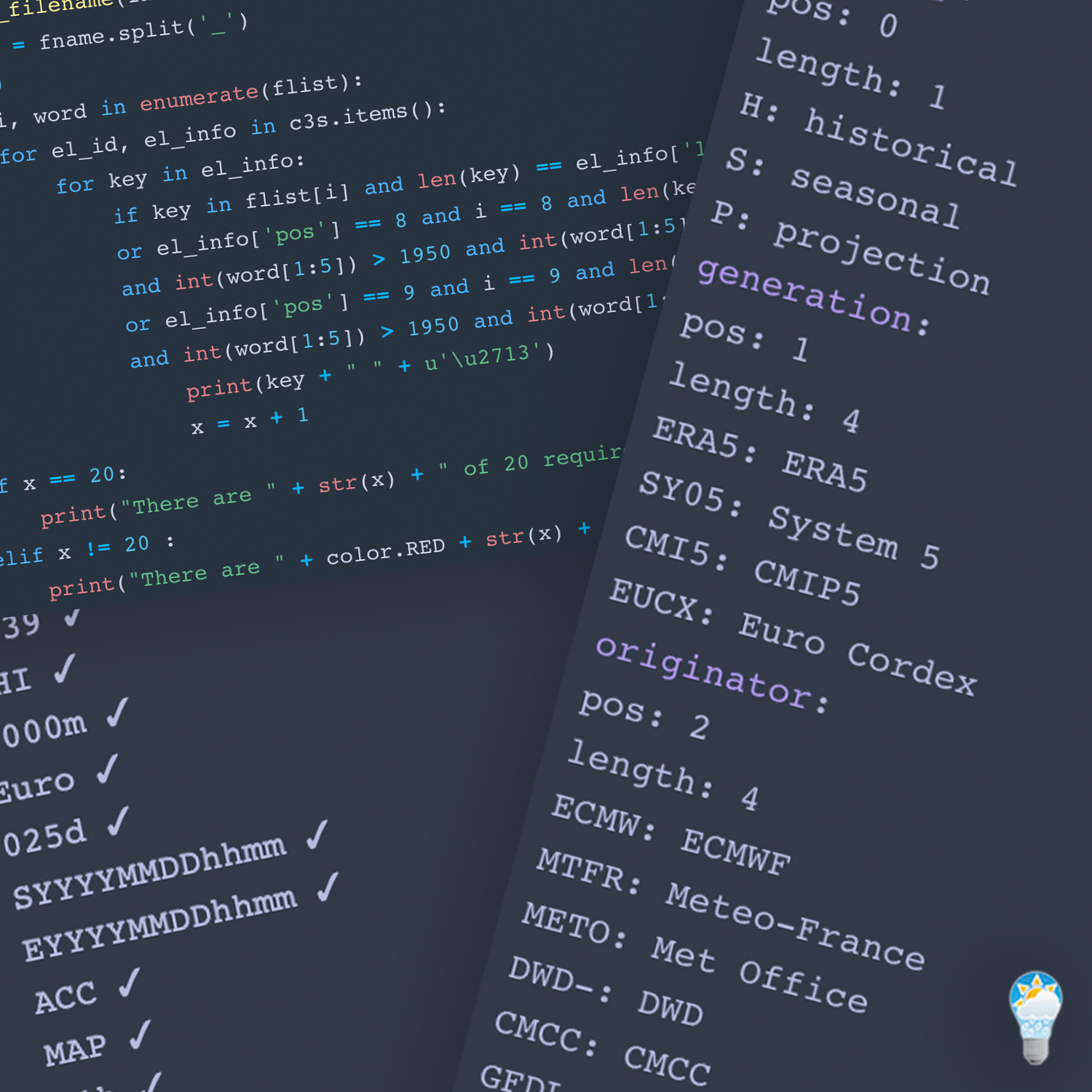
The JSON lookup table shown below contains all the allowed elements for the projects filename structure, including the associated ‘long names’ for each item (more on this later). It also contains the position of the filename element and it’s character length.
[pastacode lang=”javascript” manual=”%7B%0A%09%22category%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%200%2C%0A%09%09%22length%22%20%3A%201%2C%0A%09%09%22H%22%20%3A%20%22historical%22%2C%0A%09%09%22S%22%20%3A%20%22seasonal%22%2C%0A%09%09%22P%22%20%3A%20%22projection%22%0A%09%7D%2C%0A%09%22generation%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%201%2C%0A%09%09%22length%22%20%3A%204%2C%0A%09%09%22ERA5%22%20%3A%20%22ERA5%22%2C%0A%09%09%22SY05%22%20%3A%20%22System%205%22%2C%0A%09%09%22CMI5%22%20%3A%20%22CMIP5%22%2C%0A%09%09%22EUCX%22%20%3A%20%22Euro%20Cordex%22%0A%09%7D%2C%0A%09%22originator%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%202%2C%0A%09%09%22length%22%20%3A%204%2C%0A%09%09%22ECMW%22%20%3A%20%22ECMWF%22%2C%0A%09%09%22MTFR%22%20%3A%20%22Meteo-France%22%2C%0A%09%09%22METO%22%20%3A%20%22Met%20Office%22%2C%0A%09%09%22DWD-%22%20%3A%20%22DWD%22%2C%0A%09%09%22CMCC%22%20%3A%20%22CMCC%22%2C%0A%09%09%22GFDL%22%20%3A%20%22GFDL%22%2C%0A%09%09%22GFC2%22%20%3A%20%22GFC2%22%09%09%09%0A%09%7D%2C%0A%09%22model%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%203%2C%0A%09%09%22length%22%20%3A%204%2C%0A%09%09%22T639%22%20%3A%20%22TL%20639%22%2C%0A%09%09%22CM20%22%20%3A%20%22CM2.0%22%0A%09%7D%2C%0A%09%22variable%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%204%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22TA-%22%20%3A%20%22Air%20Temperature%22%2C%0A%09%09%22TP-%22%20%3A%20%22Total%20Precipitation%22%2C%0A%09%09%22GHI%22%20%3A%20%22Global%20Horizontal%20Irradiance%22%2C%20%0A%09%09%22MSL%22%20%3A%20%22Mean%20Sea%20Level%20Pressure%22%2C%0A%09%09%22WS-%22%20%3A%20%22Wind%20Speed%22%2C%0A%09%09%22E–%22%20%3A%20%22Evaporation%22%2C%0A%09%09%22SD-%22%20%3A%20%22Snow%20Depth%22%2C%0A%09%09%22DEM%22%20%3A%20%22Electricity%20Demand%22%2C%0A%09%09%22HRE%22%20%3A%20%22Hydropower%20(Reservoir)%22%2C%0A%09%09%22HRO%22%20%3A%20%22Hydropower%20(Run%20Of%20River)%22%2C%0A%09%20%20%20%20%22WON%22%20%3A%20%22Wind%20Power%20Onshore%22%2C%0A%09%20%20%20%20%22WOF%22%20%3A%20%22Wind%20Power%20Offshore%22%2C%0A%09%09%22WIN%22%20%3A%20%22Wind%22%2C%0A%09%09%22SPV%22%20%3A%20%22Solar%20PV%20Power%22%0A%09%7D%2C%0A%09%22level%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%205%2C%0A%09%09%22length%22%20%3A%205%2C%0A%09%09%22NA—%22%20%3A%20%22N%2FA%22%2C%20%0A%09%09%220000m%22%20%3A%20%220m%22%2C%0A%09%09%220002m%22%20%3A%20%222m%22%2C%0A%09%09%220010m%22%20%3A%20%2210m%22%2C%0A%09%09%220100m%22%20%3A%20%22100m%22%2C%0A%09%09%221e3hP%22%20%3A%20%221000%20hPa%22%2C%0A%09%09%22850hP%22%20%3A%20%22850%20hPa%22%0A%09%7D%2C%0A%09%22region%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%206%2C%0A%09%09%22length%22%20%3A%204%2C%0A%09%09%22Euro%22%20%3A%20%22Europe%22%0A%09%7D%2C%0A%09%22spacial_resolution%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%207%2C%0A%09%09%22length%22%20%3A%204%2C%0A%09%09%22025d%22%20%3A%20%220.25%20deg%22%2C%0A%09%09%22nut0%22%20%3A%20%22NUTS0%22%2C%0A%09%09%22nut2%22%20%3A%20%22NUTS2%22%0A%09%7D%2C%0A%09%22start_date%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%208%2C%0A%09%09%22length%22%20%3A%2013%2C%0A%09%09%22SYYYYMMDDhhmm%22%20%3A%20%22SYYYYMMDDhhmm%22%0A%09%7D%2C%0A%09%22end_date%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%209%2C%0A%09%09%22length%22%20%3A%2013%2C%0A%09%09%22EYYYYMMDDhhmm%22%20%3A%20%22EYYYYMMDDhhmm%22%0A%09%7D%2C%0A%09%22type%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2010%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22ACC%22%20%3A%20%22Accumulated%22%2C%0A%09%09%22INS%22%20%3A%20%22Instantaneous%22%2C%0A%09%09%22PWR%22%20%3A%20%22Power%22%2C%0A%09%09%22NRG%22%20%3A%20%22Energy%22%2C%0A%09%09%22CFR%22%20%3A%20%22Capacity%20factor%22%0A%09%7D%2C%0A%09%22view%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2011%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22MAP%22%20%3A%20%22Map%22%2C%0A%09%09%22TIM%22%20%3A%20%22Time%20series%22%0A%09%7D%2C%0A%09%22temporal_resolution%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2012%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%2201h%22%20%3A%20%221%20hour%22%2C%20%0A%09%09%2203h%22%20%3A%20%223%20hours%22%2C%0A%09%09%2206h%22%20%3A%20%226%20hours%22%2C%0A%09%09%2201d%22%20%3A%20%221%20day%22%2C%20%0A%09%09%2201m%22%20%3A%20%221%20month%22%2C%20%0A%09%09%2203m%22%20%3A%20%223%20month%22%2C%0A%09%09%2212m%22%20%3A%20%221%20year%22%2C%0A%09%09%2230y%22%20%3A%20%2230%20years%22%0A%09%7D%2C%0A%09%22lead_time%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2013%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22NA-%22%20%3A%20%22N%2FA%22%2C%0A%09%09%2203m%22%20%3A%20%223%20Months%22%0A%09%7D%2C%0A%09%22bias_adjustment%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2014%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22noc%22%20%3A%20%22No%20correction%22%2C%0A%09%09%22mbc%22%20%3A%20%22Mean%20bias%20cor%22%2C%0A%09%09%22nbc%22%20%3A%20%22Normal%20distr%20adjustment%22%2C%0A%09%09%22vbc%22%20%3A%20%22Variance%20corrected%22%2C%0A%09%09%22msd%22%20%3A%20%22Mean%20and%20std%20corrected%22%2C%0A%09%09%22std%22%20%3A%20%22Standardized%20(zero%20mean%20and%20stdev)%22%2C%0A%09%09%22wbc%22%20%3A%20%22Based%20on%20Weibull%20distr.%22%2C%0A%09%09%22gbc%22%20%3A%20%22Based%20on%20gamma%20distr.%22%2C%0A%09%09%22qbc%22%20%3A%20%22Based%20on%20quantile%20distr.n%22%2C%0A%09%09%22cdf%22%20%3A%20%22Cumulative%20distr.%20fn%22%0A%09%7D%2C%0A%09%22statistics%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2015%2C%0A%09%09%22length%22%20%3A%203%2C%0A%09%09%22org%22%20%3A%20%22Original%22%2C%0A%09%09%22avg%22%20%3A%20%22Mean%22%2C%20%0A%09%09%22med%22%20%3A%20%22Median%22%2C%20%0A%09%09%22min%22%20%3A%20%22Minimum%22%2C%20%0A%09%09%22max%22%20%3A%20%22Maximum%22%2C%0A%09%09%22and%22%20%3A%20%22Anomaly%20difference%22%2C%20%0A%09%09%22anr%22%20%3A%20%22Anomaly%20ratio%22%2C%0A%09%09%2233u%22%20%3A%20%22Upper%20tercile%22%2C%0A%09%09%2233m%22%20%3A%20%22Lower%20tercile%22%2C%0A%09%09%2220u%22%20%3A%20%22Upper%20quintile%22%2C%0A%09%09%2220l%22%20%3A%20%22Lower%20quintile%22%2C%0A%09%09%22qxx%22%20%3A%20%22Percentile%22%2C%0A%09%09%22bss%22%20%3A%20%22Brier%20skill%20score%22%2C%0A%09%09%22rss%22%20%3A%20%22Roc%20skill%20score%22%0A%09%7D%2C%0A%09%22ensemble_number%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2016%2C%0A%09%09%22length%22%20%3A%202%2C%0A%09%09%22NA%22%20%3A%20%22N%2FA%22%2C%20%0A%09%09%2201%22%20%3A%20%221%22%0A%09%7D%2C%0A%09%22emission_scenario%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2017%2C%0A%09%09%22length%22%20%3A%205%2C%0A%09%09%22NA—%22%20%3A%20%22N%2FA%22%2C%0A%09%09%22RCP45%22%20%3A%20%22RCP4.5%22%2C%20%0A%09%09%22RCP85%22%20%3A%20%22RCP8.5%22%0A%09%7D%2C%0A%09%22energy_scenario%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2018%2C%0A%09%09%22length%22%20%3A%205%2C%0A%09%09%22NA—%22%20%3A%20%22N%2FA%22%2C%0A%09%09%22EHBaM%22%20%3A%20%22E-H%202050%20Big%20and%20Market%22%2C%0A%09%09%22SHLSR%22%20%3A%20%22E-H%202050%20Large%20Scale%20Res%22%2C%0A%09%09%22EHFOF%22%20%3A%20%22E-H%202050%20Fossil%20Fuels%22%2C%0A%09%09%22EHRES%22%20%3A%20%22E-H%202050%20100%25%20RES%22%2C%0A%09%09%22EHSaL%22%20%3A%20%22E-H%202050%20Small%20and%20Local%22%2C%0A%09%09%22REF16%22%20%3A%20%22EU%20energy%20ref.%20scen.%202016%22%0A%09%7D%2C%0A%09%22transfer_function%22%20%3A%20%7B%0A%09%09%22pos%22%20%3A%2019%2C%0A%09%09%22length%22%20%3A%205%2C%0A%09%09%22NA—%22%20%3A%20%22N%2FA%22%2C%0A%09%09%22StGAM%22%20%3A%20%22Statistical%20model%2FGAM%22%2C%0A%09%09%22StMLR%22%20%3A%20%22Statistical%20model%2FMLR%3A%20StMLR%22%2C%0A%09%09%22StSVR%22%20%3A%20%22Statistical%20model%2FSVR%3A%20StSVR%22%2C%0A%09%09%22StRnF%22%20%3A%20%22Statistical%20model%2FRandom%20Forests%22%2C%0A%09%09%22GamWT%22%20%3A%20%22GAM%20With%20Trend%22%2C%0A%09%09%22GamAN%22%20%3A%20%22GAM%20Anomaly%22%2C%0A%09%09%22GamNT%22%20%3A%20%22GAM%20No%20Trend%22%2C%0A%09%09%22PhM01%22%20%3A%20%22Physical%20Model%2Fmethod1%22%0A%09%7D%0A%7D%09″ message=”JSON Lookup Table” highlight=”” provider=”manual”/]As you can see, each dictionary key has a nested dictionary within it. The key corresponds to the filename element. Here is a test example filename relevant to this project:
H_ERA5_ECMW_T639_GHI_0000m_Euro_025d_S200001010000_E200001012300_ACC_MAP_01h_NA-_noc_org_NA_NA—_NA—_NA—.nc
So referencing the JSON table, by eye it is possible to identify that the file contains historical Global Horizontal Irradiance ERA5 data, originating from ECMWF, amongst other things. This is all well and good, but what if you need to check hundreds of similar files automatically? This is where Python can be used to create some functions that call the JSON table and check the integrity of the file name string.
Import packages:
[pastacode lang=”python” manual=”%23%20import%20json%20library%0Aimport%20json%0A%23%20import%20collections%20-%20for%20ordered%20dictionary%0Aimport%20collections%0A%23%20import%20datetime%20for%20metadata%0Aimport%20datetime%0Anow%20%3D%20datetime.datetime.now()” message=”” highlight=”” provider=”manual”/]Set some font colours for printing to terminal:
[pastacode lang=”python” manual=”%23%20set%20some%20colours%20for%20printing%20to%20terminal%0Aclass%20color%3A%0A%20%20%20PURPLE%20%3D%20’%5C033%5B95m’%0A%20%20%20CYAN%20%3D%20’%5C033%5B96m’%0A%20%20%20DARKCYAN%20%3D%20’%5C033%5B36m’%0A%20%20%20BLUE%20%3D%20’%5C033%5B94m’%0A%20%20%20GREEN%20%3D%20’%5C033%5B92m’%0A%20%20%20YELLOW%20%3D%20’%5C033%5B93m’%0A%20%20%20RED%20%3D%20’%5C033%5B91m’%0A%20%20%20BOLD%20%3D%20’%5C033%5B1m’%0A%20%20%20UNDERLINE%20%3D%20’%5C033%5B4m’%0A%20%20%20END%20%3D%20’%5C033%5B0m'” message=”” highlight=”” provider=”manual”/]Load JSON file as a dictionary:
[pastacode lang=”python” manual=”%23%20load%20c3s_energy%20lookup%20table%20(json)%20as%20a%20dictionary%0Awith%20open(‘%2Fyour%2Ffile%2Fpath%2Flookup_table.json’)%20as%20c3s_json%3A%20%20%20%20%0A%20%20%20%20c3s%20%3D%20json.load(c3s_json)%0A%20%20%20%20c3s2%20%3D%20collections.OrderedDict(c3s)” message=”” highlight=”” provider=”manual”/]
A simple function to print the file name structure in the correct order, for reference purposes:
[pastacode lang=”python” manual=”%23%20function%20to%20print%20c3s_energy%20filename%20structure%0Adef%20print_structure()%3A%0A%20%20%20%20s%20%3D%20%22%22%0A%20%20%20%20for%20k%20in%20c3s2.keys()%3A%0A%20%20%20%20%20%20%20%20s%20%2B%3D%20%22%3C%22%20%2B%20color.BOLD%20%2B%20k%20%2B%20color.END%20%2B%20%22%3E_%22%20%20%20%20%0A%20%20%20%20print(s%5B%3A-1%5D%20%2B%22.nc%22)” message=”” highlight=”” provider=”manual”/]Calling this function will output the following:
[pastacode lang=”python” manual=”print_structure()%0A%0A%3Ccategory%3E_%3Cgeneration%3E_%3Coriginator%3E_%3Cmodel%3E_%3Cvariable%3E_%3Clevel%3E_%3Cregion%3E_%3Cspacial_resolution%3E_%3Cstart_date%3E_%3Cend_date%3E_%3Ctype%3E_%3Cview%3E_%3Ctemporal_resolution%3E_%3Clead_time%3E_%3Cbias_adjustment%3E_%3Cstatistics%3E_%3Censemble_number%3E_%3Cemission_scenario%3E_%3Cenergy_scenario%3E_%3Ctransfer_function%3E.nc” message=”” highlight=”” provider=”manual”/]
Another simple function to print all the possible filename elements for reference
[pastacode lang=”python” manual=”def%20print_elements()%3A%0A%20%20%20%20for%20el_id%2C%20el_info%20in%20c3s.items()%3A%0A%20%20%20%20%20%20%20%20print(color.CYAN%20%2B%20el_id%20%2B%20color.END%2B%20’%3A’)%0A%20%20%20%20%20%20%20%20for%20key%20in%20el_info%3A%0A%20%20%20%20%20%20%20%20%20%20%20%20print(key%20%2B%20’%3A’%20%2C%20el_info%5Bkey%5D)” message=”” highlight=”” provider=”manual”/]Calling this function will output the following:
[pastacode lang=”python” manual=”print_elements()%0A%0Acategory%3A%0Apos%3A%200%0Alength%3A%201%0AH%3A%20historical%0AS%3A%20seasonal%0AP%3A%20projection%0Ageneration%3A%0Apos%3A%201%0Alength%3A%204%0AERA5%3A%20ERA5%0ASY05%3A%20System%205%0ACMI5%3A%20CMIP5%0AEUCX%3A%20Euro%20Cordex%0Aoriginator%3A%0Apos%3A%202%0Alength%3A%204%0AECMW%3A%20ECMWF%0AMTFR%3A%20Meteo-France%0AMETO%3A%20Met%20Office%0ADWD-%3A%20DWD%0ACMCC%3A%20CMCC%0AGFDL%3A%20GFDL%0AGFC2%3A%20GFC2%0Amodel%3A%0Apos%3A%203%0Alength%3A%204%0AT639%3A%20TL%20639%0ACM20%3A%20CM2.0%0Avariable%3A%0Apos%3A%204%0Alength%3A%203%0ATA-%3A%20Air%20Temperature%0ATP-%3A%20Total%20Precipitation%0AGHI%3A%20Global%20Horizontal%20Irradiance%0AMSL%3A%20Mean%20Sea%20Level%20Pressure%0AWS-%3A%20Wind%20Speed%0AE–%3A%20Evaporation%0ASD-%3A%20Snow%20Depth%0ADEM%3A%20Electricity%20Demand%0AHRE%3A%20Hydropower%20(Reservoir)%0AHRO%3A%20Hydropower%20(Run%20Of%20River)%0AWON%3A%20Wind%20Power%20Onshore%0AWOF%3A%20Wind%20Power%20Offshore%0AWIN%3A%20Wind%0ASPV%3A%20Solar%20PV%20Power%0Alevel%3A%0Apos%3A%205%0Alength%3A%205%0ANA—%3A%20N%2FA%0A0000m%3A%200m%0A0002m%3A%202m%0A0010m%3A%2010m%0A0100m%3A%20100m%0A1e3hP%3A%201000%20hPa%0A850hP%3A%20850%20hPa%0Aregion%3A%0Apos%3A%206%0Alength%3A%204%0AEuro%3A%20Europe%0Aspacial_resolution%3A%0Apos%3A%207%0Alength%3A%204%0A025d%3A%200.25%20deg%0Anut0%3A%20NUTS0%0Anut2%3A%20NUTS2%0Astart_date%3A%0Apos%3A%208%0Alength%3A%2013%0ASYYYYMMDDhhmm%3A%20SYYYYMMDDhhmm%0Aend_date%3A%0Apos%3A%209%0Alength%3A%2013%0AEYYYYMMDDhhmm%3A%20EYYYYMMDDhhmm%0Atype%3A%0Apos%3A%2010%0Alength%3A%203%0AACC%3A%20Accumulated%0AINS%3A%20Instantaneous%0APWR%3A%20Power%0ANRG%3A%20Energy%0ACFR%3A%20Capacity%20factor%0Aview%3A%0Apos%3A%2011%0Alength%3A%203%0AMAP%3A%20Map%0ATIM%3A%20Time%20series%0Atemporal_resolution%3A%0Apos%3A%2012%0Alength%3A%203%0A01h%3A%201%20hour%0A03h%3A%203%20hours%0A06h%3A%206%20hours%0A01d%3A%201%20day%0A01m%3A%201%20month%0A03m%3A%203%20month%0A12m%3A%201%20year%0A30y%3A%2030%20years%0Alead_time%3A%0Apos%3A%2013%0Alength%3A%203%0ANA-%3A%20N%2FA%0A03m%3A%203%20Months%0Abias_adjustment%3A%0Apos%3A%2014%0Alength%3A%203%0Anoc%3A%20No%20correction%0Ambc%3A%20Mean%20bias%20cor%0Anbc%3A%20Normal%20distr%20adjustment%0Avbc%3A%20Variance%20corrected%0Amsd%3A%20Mean%20and%20std%20corrected%0Astd%3A%20Standardized%20(zero%20mean%20and%20stdev)%0Awbc%3A%20Based%20on%20Weibull%20distr.%0Agbc%3A%20Based%20on%20gamma%20distr.%0Aqbc%3A%20Based%20on%20quantile%20distr.n%0Acdf%3A%20Cumulative%20distr.%20fn%0Astatistics%3A%0Apos%3A%2015%0Alength%3A%203%0Aorg%3A%20Original%0Aavg%3A%20Mean%0Amed%3A%20Median%0Amin%3A%20Minimum%0Amax%3A%20Maximum%0Aand%3A%20Anomaly%20difference%0Aanr%3A%20Anomaly%20ratio%0A33u%3A%20Upper%20tercile%0A33m%3A%20Lower%20tercile%0A20u%3A%20Upper%20quintile%0A20l%3A%20Lower%20quintile%0Aqxx%3A%20Percentile%0Abss%3A%20Brier%20skill%20score%0Arss%3A%20Roc%20skill%20score%0Aensemble_number%3A%0Apos%3A%2016%0Alength%3A%202%0ANA%3A%20N%2FA%0A01%3A%201%0Aemission_scenario%3A%0Apos%3A%2017%0Alength%3A%205%0ANA—%3A%20N%2FA%0ARCP45%3A%20RCP4.5%0ARCP85%3A%20RCP8.5%0Aenergy_scenario%3A%0Apos%3A%2018%0Alength%3A%205%0ANA—%3A%20N%2FA%0AEHBaM%3A%20E-H%202050%20Big%20and%20Market%0ASHLSR%3A%20E-H%202050%20Large%20Scale%20Res%0AEHFOF%3A%20E-H%202050%20Fossil%20Fuels%0AEHRES%3A%20E-H%202050%20100%25%20RES%0AEHSaL%3A%20E-H%202050%20Small%20and%20Local%0AREF16%3A%20EU%20energy%20ref.%20scen.%202016%0Atransfer_function%3A%0Apos%3A%2019%0Alength%3A%205%0ANA—%3A%20N%2FA%0AStGAM%3A%20Statistical%20model%2FGAM%0AStMLR%3A%20Statistical%20model%2FMLR%3A%20StMLR%0AStSVR%3A%20Statistical%20model%2FSVR%3A%20StSVR%0AStRnF%3A%20Statistical%20model%2FRandom%20Forests%0AGamWT%3A%20GAM%20With%20Trend%0AGamAN%3A%20GAM%20Anomaly%0AGamNT%3A%20GAM%20No%20Trend%0APhM01%3A%20Physical%20Model%2Fmethod1″ message=”” highlight=”” provider=”manual”/]
Finally, this function will check the filename string against the JSON table and output if there are the correct amount of elements present in the string. This takes one argument, your filename as string (fname) as input.
[pastacode lang=”python” manual=”%23%20function%20to%20check%20a%20filename%20meets%20JSON%20lookup%20table%0Adef%20check_filename(fname)%3A%0A%20%20%20%20flist%20%3D%20fname.split(‘_’)%0A%20%20%20%20x%20%3D%200%0A%20%20%20%20for%20i%2C%20word%20in%20enumerate(flist)%3A%0A%20%20%20%20%20%20%20%20for%20el_id%2C%20el_info%20in%20c3s.items()%3A%0A%20%20%20%20%20%20%20%20%20%20%20%20for%20key%20in%20el_info%3A%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20if%20key%20in%20flist%5Bi%5D%20and%20len(key)%20%3D%3D%20el_info%5B’length’%5D%20and%20el_info%5B’pos’%5D%20%3D%3D%20i%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20or%20el_info%5B’pos’%5D%20%3D%3D%208%20and%20i%20%3D%3D%208%20and%20len(key)%20%3D%3D%20el_info%5B’length’%5D%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20and%20int(word%5B1%3A5%5D)%20%3E%201950%20and%20int(word%5B1%3A5%5D)%20%3C%203000%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20or%20el_info%5B’pos’%5D%20%3D%3D%209%20and%20i%20%3D%3D%209%20and%20len(key)%20%3D%3D%20el_info%5B’length’%5D%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20and%20int(word%5B1%3A5%5D)%20%3E%201950%20and%20int(word%5B1%3A5%5D)%20%3C%203000%3A%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20print(key%20%2B%20%22%20%22%20%2B%20u’%5Cu2713′)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20x%20%3D%20x%20%2B%201%0A%20%20%20%20if%20x%20%3D%3D%2020%3A%0A%20%20%20%20%20%20%20%20print(%22There%20are%20%22%20%2B%20str(x)%20%2B%20%22%20of%2020%20required%20elements%20in%20the%20filename%20%22)%0A%20%20%20%20elif%20x%20!%3D%2020%20%3A%0A%20%20%20%20%20%20%20%20print(%22There%20are%20%22%20%2B%20color.RED%20%2B%20str(x)%20%2B%20color.END%20%2B%20%22%20of%2020%20required%20elements%20in%20the%20filename%22)%20%20%20%20%20%20%20%20%20%20%20%20″ message=”” highlight=”” provider=”manual”/]Taking the example filename as a string and passing it to the function, gives the following output:
[pastacode lang=”python” manual=”fname%20%3D%20’H_ERA5_ECMW_T639_GHI_0000m_Euro_025d_S200001010000_E200001012300_ACC_MAP_01h_NA-_noc_org_NA_NA—_NA—_NA—.nc’%0Acheck_filename(fname)%0A%0AH%20%E2%9C%93%0AERA5%20%E2%9C%93%0AECMW%20%E2%9C%93%0AT639%20%E2%9C%93%0AGHI%20%E2%9C%93%0A0000m%20%E2%9C%93%0AEuro%20%E2%9C%93%0A025d%20%E2%9C%93%0ASYYYYMMDDhhmm%20%E2%9C%93%0AEYYYYMMDDhhmm%20%E2%9C%93%0AACC%20%E2%9C%93%0AMAP%20%E2%9C%93%0A01h%20%E2%9C%93%0ANA-%20%E2%9C%93%0Anoc%20%E2%9C%93%0Aorg%20%E2%9C%93%0ANA%20%E2%9C%93%0ANA—%20%E2%9C%93%0ANA—%20%E2%9C%93%0ANA—%20%E2%9C%93%0AThere%20are%2020%20of%2020%20required%20elements%20in%20the%20filename%20″ message=”” highlight=”” provider=”manual”/]The motive behind creating these functions, is they can then be called from another Python script running on a system, be that a local machine, virtual machine, server, HPC etc.
This can be achieved simply by adding the following to the top of your script (the functions are saved in a python file called ‘filename_utilities.py’):
[pastacode lang=”python” manual=”%23%20import%20c3s%20filename%20utilities%0Aimport%20sys%0Asys.path.append(os.path.abspath(%22%2Fyour%2Fpath%2Fhere%2F%22))%0Afrom%20filename_utilities%20import%20print_structure%2C%20print_elements%2C%20check_filename” message=”” highlight=”” provider=”manual”/]
So what’s the use in having all the long names in the JSON? This comes in handy when we need to produce data in a human readable format, such as writing metadata and comments. The next blog will focus on parsing the JSON file to automatically generate metadata as comments into an outputted CSV file.
by Luke Sanger (WEMC Data Engineer, 2019)



{kind=link}